
论文基本信息
论文标题:Exploiting the Matching Information in the Support Set for Few Shot Event Classification
论文作者:Viet Dac Lai, Franck Dernoncourt, and Thien Huu Nguyen1
论文出处:PAKDD2020
论文原文地址:https://arxiv.xilesou.top/pdf/2002.05295.pdf
论文正文
摘要:现有的事件分类(EC)工作主要集中在传统的有监督的学习环境中,在这种环境中,模型无法提取新的/不可见的事件类型。在这一领域还没有对few-shot学习进行研究,尽管它使EC模型能够将其操作扩展到未观察到的事件类型。为了填补这一空白,在这项工作中,我们研究了在few-shot学习背景下的事件分类。针对这一问题,我们提出了一种新的训练方法,该方法广泛利用了训练过程中的支持集。特别是,除了将查询示例与用于训练的支持集中的示例进行匹配外,我们还寻求进一步匹配支持集本身中的示例。该方法为模型提供了更多的训练信号,可以应用于各种基于度量学习的few-shot学习方法。我们在两个基准的EC数据集上进行了大量的实验,结果表明所提出的方法可以将所报告的最佳few-shot学习模型的事件分类准确率提高10%。
关键词:事件分类,辅助损失,few-shot学习
Introduction
事件分类(EC)是自然语言处理(NLP)中信息抽取(IE)的一项重要工作。EC的目标是对一些事件类型集(即类)的事件提及(Event mentions)进行分类。事件提及(Event mentions)通常与一些词汇/短语相关,这些词汇/短语负责触发句子中相应的事件。例如,考虑以下两句话:
(1) The companies fire the employee who wrote anti-diversity memo.
(2) The troops were ordered to cease fire.
在这些示例中,EC系统应该能够将上述两句话中的“fire”分别归类为雇佣终止事件和攻击事件。通过例子可以看出,EC中一个值得注意的挑战是,单词的相似表面形式可能会根据上下文表达不同的事件。EC采用了两种主要方法。第一种方法探索语言特征(例如,语法和语义属性)来训练统计模型[9]。另一方面,第二种方法侧重于开发深度神经网络模型(例如卷积神经网络(CNN)和递归神经网络(RNN)),以从大规模数据集中自动学习有效特征[5,13]。由于深度学习模型的发展,EC的性能得到了显著的提高[19,17,16,14,23]。
目前的EC模型主要采用传统的监督学习设置[19,17],其中用于分类的事件类型集合已经被预先确定。然而,一旦使用给定的事件类型集在数据集上对模型进行训练,它就无法检测到不可见事件类型的事件提及(Event mentions)。要将EC扩展到新的事件类型,一种常见的解决方案是为此类新事件类型注释额外的培训数据并重新培训模型,这是非常昂贵的。因此,我们希望在few-shot学习的环境中形式化EC,在这种环境中,系统需要学习从少数例子中识别新事件类型的事件提及(Event mentions)。事实上,这更接近于人类如何学习执行任务,并使EC模型更适用于实践。然而,据我们所知,目前还没有关于few-shot学习的研究。
在few-shot学习中,我们得到了一个支持集和一个查询实例。支持集包含一组类的示例(例如EC中的事件)。学习模型需要在支持集中显示的类中预测查询实例所属的类。这是基于查询示例和支持集中的示例之间的匹配信息完成的。要应用此设置来提取某个新类型的示例,我们只需要收集几个新类型的示例,然后将它们添加到支持集中以形成一个新类。之后,每当我们需要预测一个新示例是否具有新类型时,我们可以将其设置为查询示例并在此设置中执行模型。
实际上,我们经常有一些现有的数据集(用D表示),并带有一些预定义类型的示例。因此,先前关于few-shot学习的工作已经利用这些数据集来模拟前面提到的few-shot学习设置来训练模型[26]。基本上,在培训过程的每个阶段,都会对D中的类型子集进行采样,并为每个类型选择一些示例作为支持集。还从每种抽样类型的其余示例中选择了一些其他示例来建立查询点。然后,将根据示例的上下文匹配对模型进行训练,以将查询示例正确映射到支持集中的相应类型[7]。
此训练过程的一个潜在问题是,模型的训练信号仅来自查询示例和支持集中的示例之间的匹配信息。现有的few-shot学习工作[28,26],特别是对于NLP任务[7],还没有探索支持集本身中示例之间的可用匹配信息。虽然这种方法对于计算机视觉中的任务是可以接受的,但是对于NLP应用程序,特别是对于EC,可能就不太合适了。总体而言,NLP中的数据集比计算机视觉中的数据集要小得多,因此限制了用于训练目的的上下文的多样性。对支持集中的示例的匹配信息的不了解可能会导致在EC训练数据的使用中效率低下,因为模型无法充分利用可用信息并且无法获得良好的性能。因此,在这项工作中,我们建议同时利用支持集中的示例之间以及查询示例与支持集中的示例之间的匹配信息,以训练EC的少量学习模型。这是通过在损失函数中添加附加项(即辅助损失)来实现的,以捕获支持集中的示例之间的匹配知识。我们期望这种新的训练技术能更好地利用训练数据,提高EC中few-shot学习的性能。
我们将提出的训练方法广泛应用于不同的度量学习模型,以便在两个基准EC数据集上进行few-shot学习。实验表明,新的训练技术可以在性能差距较大的两个数据集上显著改善所有考虑的few-shot学习方法。总而言之,这项工作的贡献包括: (1)我们在文献中首次研究了事件分类的few-shot学习问题,(2)提出了一种新的基于度量学习的few-shot学习模型训练方法。所提出的训练方法利用支持集中的例子之间的匹配信息作为附加训练信号,(3)我们在few-shot学习环境中获得了EC的最新性能,并作为该领域未来研究的基准。
Related Work
早期的事件分类研究主要集中在为统计模型设计语言特征[1,9,12]。由于深度学习的发展,许多先进的网络结构被用来提高事件分类的准确性[5,19,17,18,21,13,22]。然而,没有一个像我们在这项工作中所做的那样,为EC研究few-shot学习问题。虽然最近的一些研究已经考虑了一个相关的设置,其中事件类型用一些关键字进行了扩充[3,24,11],但这些工作并没有像我们在这项工作中所做的那样明确地检查few-shot学习设置。本文还对事件分类中的zero-shot学习进行了一些研究[8]。
Few-shot学习有助于模型在没有大规模数据的情况下学习有效的潜在特征。早期的研究将迁移学习应用于对预先训练好的模型进行微调,利用足够的实例从公共类中挖掘潜在的信息[4,2]。另一方面,度量学习则是学习对观察到的类之间的距离分布进行建模[10,28,26]。最近,元学习中引入了快速学习的概念,这种学习可以很快地概括为一个新的概念[25,6]。在这些方法中,与迁移学习和元学习相比,度量学习更易于解释,更易于训练和实施。值得注意的是,度量学习中的典型网络在几个FSL基准上取得了最新的性能,并显示了其对噪声数据的鲁棒性[26,7]。虽然有许多FSL方法被提出用于图像识别[10,28,26,6,25],但是针对NLP问题的这种设置的研究很少[7,29]。
Methodology
Notation
Few-shot事件分类的任务是在给定一个支持集S和一组事件类型T={t1,t2,tN}(N是事件类型的数目),来预测查询示例x的事件类型。在few-shot学习中,S包含了T中每个事件类型的几个示例。为了方便起见,我们将支撑集表示为: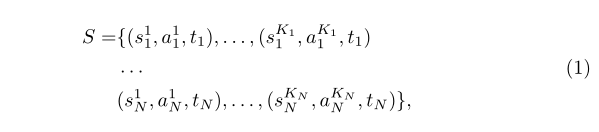
其中(s_i^j,a_i^j,t_i)表示s_i^j语句中的a_i^j-th单词是事件类型t_i提到的触发单词,K_1,K_2,…,K_N分别代表的是对于t_1,t_2,…,t_N中的每一种类型在支持集中的示例数量。为了简单起见,我们使用w_1,w_2,…,w_l表示在这项工作中某个长度为l的句子的单词序列。
类似地,查询示例x也可以用x=(q,p,t)表示,其中q,p和t分别表示查询语句、语句中触发词的位置和该事件提及的真正事件类型。注意t∈T只在训练时间内提供,模型需要在测试时间内预测该事件类型。
实际上,S中的支持示例的数量(即K_1,K_2,…,K_N)可能有所不同。但是,为了简化处理并使用GPU加快训练过程,类似于FSL中的最新研究[7],我们采用了N-way K-shot FSL设置。在此设置中,支持集中每个类的实例数相等(K_1=⋯ K_N=K>1)和小(K∈{5,10})。
请注意,为了评估EC的few-shot学习模型,我们需要训练数据Dtrain和测试数据Dtest。对于few-shot学习,关键是Dtrain和Dtest中的事件类型集合是不相交的。每一集的事件类型集合T将是Dtrain或Dtest中事件类型集合的一个样本,分别取决于训练和评估时间。另外,如引言中所述,在训练过程的一个阶段中,将对一组查询示例(即查询集)进行采样,以使其涉及与支持集相似的事件类型T,以及每种类型的示例查询集中的内容将与支持集中的内容不同。在测试时,将对测试集中所有样本的模型分类精度进行评估。
Few-shot Learning for Event Classification
本工作中EC的few-shot学习框架遵循典型网络中的典型度量学习结构[26,7],涉及到三个主要组件:实例编码器(instance encoder)、原型模块(prototypical module)、分类器模块(classifier module)。
Instance encoder
给定一个句子s={w_1,w_2,…,w_l}和触发词a的位置(即w_a是在句子s中事件提及的触发词,(s,a)是S或查询示例中的示例),遵循EC[19,5]中的一般做法,我们首先将每个单词w_i∈s转换成实值向量,以便于在接下来的步骤中进行神经计算。特别是,在这项工作中,我们使用以下两个向量的连接来表示每个单词w_i:
- w_i的预训练词嵌入:这个向量被期望用来捕获w_i隐藏的语法和语义信息[15]。
- w_i的位置嵌入:该向量是通过将其与触发词w_a(即i - a)的相对距离映射到位置嵌入表中的嵌入向量而获得的。位置嵌入表在模型训练过程中随机初始化和更新。位置嵌入向量的目的是明确地告知模型触发词在句子中的位置[5]。
在将w_i转换成表示向量ei之后,输入语句s成为表示向量E = e1,e2,…el的序列。基于这个向量序列,一个神经网络结构f将会被用来将E转换成一个整体的表示向量v来对输入的例子(s, m)进行编码(v = f(s, m))。在这项工作中,我们研究了编码函数f的两种网络架构,即一个是基于CNN的早期EC架构,另一个是基于Transformer的最近流行的NLP架构:
CNN encoder: 该模型对输入向量序列E进行窗口大小为k和多个滤波器的时域卷积运算,对输入语句的每个位置生成一个隐藏向量。然后通过最大池操作对这些隐藏向量进行聚合,得到(s, m)的整体表示向量v[5,7]。
Transformer encoder:这是一种先进的基于注意机制的矢量序列编码模型,不需要递归神经网络[27]。Transformer 编码器(encoder)涉及多层; 它们中的每一个都使用来自前一层的隐藏向量序列来生成当前层的隐藏向量序列。第一层以E为输入,而最后一层返回的隐藏向量序列(即触发字位置a处的向量)构成整个表示向量v。transformer编码器中的每一层都由两个子层(即多头的自我关注层和前馈层)组成,并在其周围增加一个剩余连接[27]。
Prototypical module
原型模块旨在计算单个原型向量来表示支持集T中的每个类。在这项工作中,我们考虑了文献中这个原型模块的两个版本。第一个版本来自原始的原型网络[26]。它仅使用支持集S中事件类型为ti的示例的表示向量的平均值来获取类ti的原型向量ci: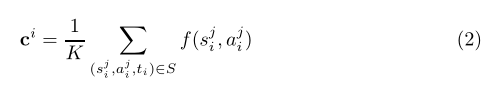
另一方面,第二个版本来自基于混合注意力的原型网络[7]。原型向量是支持集中实例的表示向量的加权和。示例权重(即注意力权重)是由支持集中的示例与查询示例x = (q, p, t)的相似度决定的: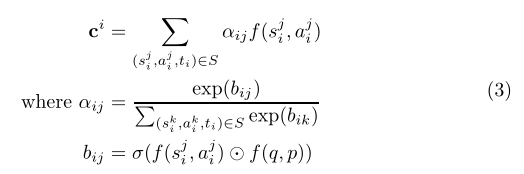
在这个公式中,⊙是逐元素的乘法,sum是在输入向量的所有维度上进行的求和运算。
Classifier module
在本模块中,我们使用查询示例x = (q, p, T)到支持集中类/事件类型T的原型的距离,计算x在T中可能的类型的概率分布: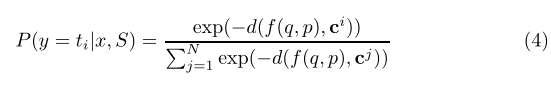
其中d为距离函数,ci和cj分别为式(2)和式(3)中的原型向量。
在本文中,我们考虑了三种常用的距离函数在不同的few-shot学习模型中使用度量学习:
- 匹配网络中的余弦相似度(称为Matching)[28]。
- 原型网络中的欧氏距离。根据原型向量是用方程2还是用方程3来计算,我们有两种不同的距离函数,分别称为Proto[26]和Proto+Att(即基于混合注意的原型网络[7])。
- 在关系网络中使用卷积神经网络的可学习距离函数(称为Relation)。给定概率分布P(y | x,S),训练few-shot学习框架的典型方法是优化x的负对数似然函数(t为x的基本真值事件类型)[26,7]:
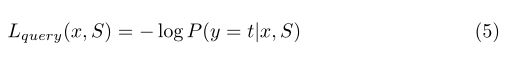
Matching the examples in the support set
等式5中的典型few-shot学习损失函数旨在通过原型向量将查询示例x与支持集S中的示例匹配来学习的。这种机制的一个问题是它只使用查询示例和支持示例之间的匹配信号进行训练。这对于大型数据集(例如,在计算机视觉中)是可以接受的,其中许多示例可以扮演查询示例的角色,为学习过程提供足够的训练信号。然而,对于EC,可用的数据集通常很小(例如,ACE 2005数据集只有大约几千个带注释的事件提及),这使得仅依赖查询示例来训练信号的效率降低。换言之,对于EC查询匹配的有限数据,few-shot学习框架可能无法得到很好的训练。因此,在这项工作中,我们提出通过额外利用支持集中的实例之间的匹配信息,为EC引入更多的训练信号以进行few-shot学习。特别是,由于支持集中每个类/类型有多个示例(尽管只有几个),因此我们为S中的每种类型选择了此类示例的子集,并增强模型使其能够将所选示例与其剩余支持集中的相应类型进行匹配。
在给定辅助支持集s^s的情况下,通过将辅助查询集S^Q中的示例与s^s进行匹配,寻求增强few-shot模型的训练信号。具体来说,我们首先在实例编码器和原型模块中使用相同的网络来计算辅助支持集s^s的T类的辅助原型。对于每个辅助实例z=(s_z,a_z,t_z)∈S^Q(s_z,a_z 和t_z分别是z中的句子、触发词位置和事件类型),我们使用分类器模块中的网络,基于辅助支持集s^s获得z中可能事件类型的概率分布P(.| z,s^s)。之后,我们通过引入辅助损失函数,增强模型可以正确预测辅助查询集S_ⅈ^Q中所有示例的事件类型(给定支持集s^s):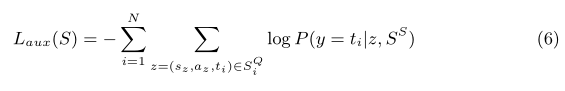
最后,本文中训练模型所需优化的总损失函数为: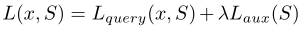
其中λ是主损失函数和辅助损失函数之间的权衡参数。为了方便起见,在以下实验中,我们将用于few-shot学习中具有辅助损失功能的训练方法称为LoLoss(即遗忘损失)。
Experiments
Datasets
我们在ACE 2005上评估了本研究中的所有模型。ACE 2005包含33个事件子类型,分为8种事件类型:业务(Business)、联系(Contact)、冲突(Conflict)、正义(Justice)、生活(Life)、移动(Movement)、人员(Personnel)和事务(Transaction)。另一方面,TAC KBP数据集包含9种事件类型的38个事件子类型。由于事件子类型的数量较多,我们将使用这些数据集中的子类型作为few-shot学习问题的类。
由于我们希望在训练数据中最大化示例的数量,对于每个数据集(即,ACE 2005或TAC KBP 2015),我们在4个事件类型中选择示例总数最少的事件子类型,并以1:1的比率拆分为测试和开发类。按照这种启发式方法来选择类,ACE 2005中用于训练数据的事件类型涉及业务(Business)、联系(Contact)、冲突(Conflict)和正义(Justice),而用于测试和开发数据的事件类型是生活(Life)、移动(Movement)、人员(Personnel)和事务(Transaction)。对于TAC KBP 2015,培训课程包括业务(Business)、联系(Contact)、冲突(Conflict)、正义(Justice)和制造(Manufacture),而测试和开发课程包括生活(Life)、移动(Movement)、人员(Personnel)和事务(Transaction)。最后,由于打算遵循先前的几次学习的工作,在支持集中每个类有10个示例,在查询集中每个类有5个示例进行训练[7],因此我们删除了在数据集的训练,测试和开发集中少于15个示例的任何子类型的示例。
Hyper-Parameters
类似于先前的工作[7],我们使用N,K∈{5,10}的N-way K-shot FSL设置评估所有模型。对于训练,我们避免在每个批次中输入相同的事件子类型集,以使训练批次更加多样化。因此,根据文献[7],我们为每个培训批次采样了20个事件子类型,同时在测试时间内仍保留5个或10个类。
我们使用预先训练的300维GloVe嵌入初始化单词嵌入。单词嵌入在训练期间如文献[20]中所述进行更新。我们还随机初始化了50维的位置嵌入向量。根据数据集的开发数据选择其他参数,从而导致ACE 2005和TAC KBP 2015的参数相似。尤其是,CNN编码器包含一个窗口大小为3和250个过滤器的CNN层。我们设法使用这个简单的CNN编码器与之前的研究进行公平的比较[7]。Transformer编码器在注意机制中包含2个层,上下文大小为512,并且包含10个头部。辅助查询集Q中每个类别的示例数设置为2,而损失函数中的权衡参数λ为0.1。我们使用学习率为0.001的随机梯度下降来优化模型。
Results
表1显示了使用CNN编码器和Transformer编码器的ACE 2005测试数据集上模型的准确性(即Matching、Proto、Proto+Att和Relation)。从表中可以看出几点。首先,比较实例编码器,很明显,在所有可能的few-shot学习模型和EC设置中,transformer编码器明显优于CNN编码器。第二,与few-shot学习模型相比,原型网络在所有设置下都显著优于Matching 和Relation,且性能差距较大。在原型网络中,Proto+Att的性能优于Proto,验证了原型模块基于注意机制的优点。第三,比较两组(5-way 5-shot VS 5-way 10-shot)和(10-way 5-shot VS 10-way 10-shot),我们发现在不同的设置下,当K值较大(即支持集中每个类的示例数)时,模型的性能几乎总是更好的,与自然直觉一致,即有更多的训练实例的好处。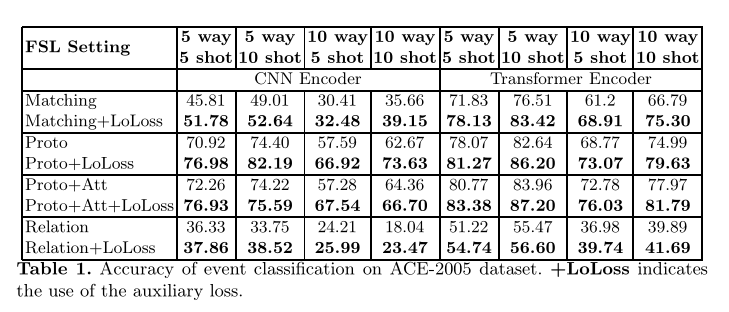
最重要的是,我们发现使用LoLoss程序训练模型将显著提高模型的性能。这适用于不同的few-shot学习模型、N-way k -shot设置和编码器选择。实验结果清楚地证明了所提出的训练程序利用支持集中的示例之间的匹配信息进行EC的few-shot学习的有效性。为简单起见,在下面的分析中,我们仅关注最佳的few-shot学习模型(即原型网络)和5-way 5-shot 与10-way 10-shot下的Transformer编码器。尽管我们在表2和表3中以较少的设置和模型显示了结果,但对于其他模型和设置也观察到了相同的趋势。
表2还报告了TAC KBP 2015数据集上基于transformer的模型的准确性。从表中可以看出,我们对ACE 2005数据集的大部分观察结果仍然适用于TAC KBP 2015,再次证实了本文提出的LoLoss技术的优势。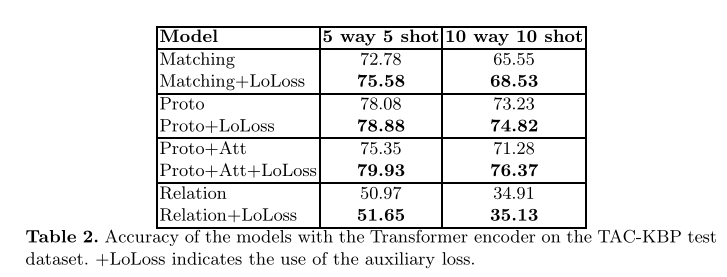
Robustness against noise
在这一部分中,我们试图评估few-shot学习模型对训练数据中可能存在的噪声的鲁棒性。特别地,在每一个训练集中,对T中的每种类型采样一组示例以形成查询集Q,我们通过随机选择Q中的一部分示例进行标签扰动来模拟噪声数据。本质上,对于Q的选定子集中的每个示例,我们将其原始标签更改为T中的另一个随机标签,使其成为带有错误标签的噪声示例。通过更改Q中用于标签扰动的选定部分的大小,我们可以控制EC中FSL训练过程中的噪声水平。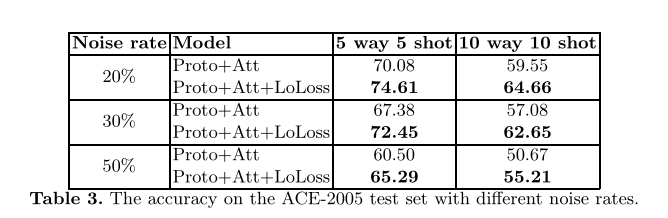
表3显示了Proto + Att模型在ACE 2005测试集上的准确性,该模型采用带有或不带有LoLoss训练程序的Transformer编码器以用于不同的噪声率。从表中可以看出,引入噪声数据通常会降低模型的准确性(即,将表3中的单元与表1中基于Proto + Att的模型进行比较)。然而,在不同的噪声率和N-way K-shot设置下,使用LoLoss训练的Proto+Att模型始终明显优于未使用LoLoss的模型。在不同的设置下,性能差距至少是4.5%。事实上,我们发现LoLoss对Proto+Att的改善在有噪声的情况下(即至少4.5%)比无噪声的情况下更加显著(即。在表1中,5-way 5-shot 和10-way 10-shot的设置最多为3.3%)。这些证据进一步证实了LoLoss利用支持集中样本间的匹配信息来进行fen-shot学习的有效性和对噪声数据的鲁棒性。
Conclusion
在这篇论文中,我们进行了第一个研究few-shot学习的事件分类。我们针对此问题研究了不同的量度学习方法,以典型的原型网络框架为特色,并为实例编码器(即CNN和Transformer)提供了多种选择。此外,我们提出了一种新的技术,称为LoLoss,用于训练基于支持集实例匹配信息的EC的few-shot学习模型。提出的LoLoss技术适用于不同数据集和设置的不同few-shot学习方法,有助于显著提高基线模型的性能。在未来,我们计划对LoLoss进行few-shot学习,以解决其他NLP和视觉问题(如关系提取、图像分类)。
Acknowledgments
This research has been supported in part by Vingroup Innovation Foundation (VINIF) in project code VINIF.2019.DA18 and Adobe Research Gift. This research is also based upon work supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Pro
References
略!
